
Research
Current Funded Projects
Institute for Student-AI Teaming

Modeling Causality in AI Through Embodiment and Analogy
Platform Accelerating Rural Access to Distributed Integrated Medical Care
Selected Past Funded Projects

Friction for Accountability in Conversational Transactions
Embodied Computational Metacognition

BabyBAW
Active Interpretation of Disparate Alternatives

Communicating With Computers
iSAT
iSAT (the Institute for Student AI Teaming) is one of the inaugural NSF-funded AI Institutes, led by the University of Colorado Boulder.
The goal of iSAT is to build AI agents that can assist small groups engaged in STEM learning by observing student interactions and group dynamics. AI in education can play the role of an expert, a near-peer, or a co-learner. We are interested not in the traditional intelligent tutoring system paradigm, but in the use of AI to help teams of students learn better by helping them engage in the social practice of science.
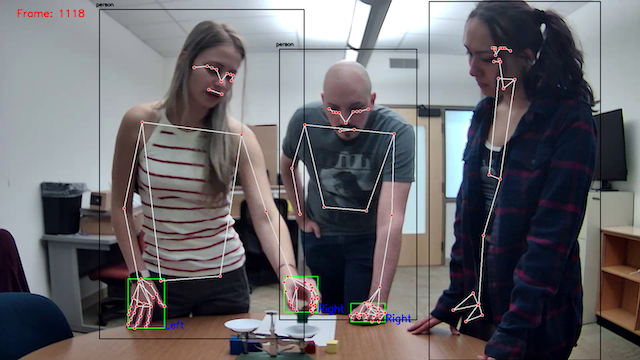
My group's work in iSAT is primarily concerned with the modeling of multimodal interaction during collaborative tasks. This includes recognizing gestures, grounding objects in context and reasoning about their relationship to the task at hand, and detecting collaborative problems solving skills from multimodal inputs. In the image below, we see some students in the lab engaged in a collaborative task, where we automatically track the people, their hands, and their skeletons.
iSAT originally ran from 2020-2025 but was fortunately renewed through 2030 to perform more outreach and deployment in classrooms. We are transitioning our work in multimodal common ground tracking and collaborative problem solving from the DARPA FACT program into this renewal effort.

Modeling Causality in AI Through Embodiment and Analogy
Modeling Causality in AI Through Embodiment and Analogy is a project funded by the Army Research Office through the Knowledge Systems Program. We seek to imbue AI systems, primarily those driven by LLMs, with robust physical causal models that enable them to problem solve semi-independently or in collaboration with humans.
This project uses both simulation-based approaches (as in Embodied Computational Metacognition) and collaborative knowledge sharing (as in FACT) to source and distill knowledge of physical causality into LLMs. Our primary hypothesis is that the way an agent is embodied and situated in an environment conditions its ability to model physical causality.
The image below shows a sample Rube Goldberg machine-style setup wherein an AI system would have to use its understanding of physics and causality to assemble an arbitrary collection of components to correctly achieve a predefined goal, such as knocking over both sets of dominos using only the two silver balls dropped at the same time.

PARADIGM
The ARPA-H PARADIGM (Platform Accelerating Rural Access to Distributed InteGrated Medical Care) program seeks to improve healtcare outcomes for rural American though a mobile "care delivery platform" (CDP) that can bring hospital-level care to rural locations that lack access to these services.
Our team, part of a larger effort led by the University of Michigan, is working to develop an intelligent "task-guidance" upskilling platform that can guide local medical personnel through more advanced procedures in real time by providing just-in-time multimodal interventions to support task completion and prevent mistakes.
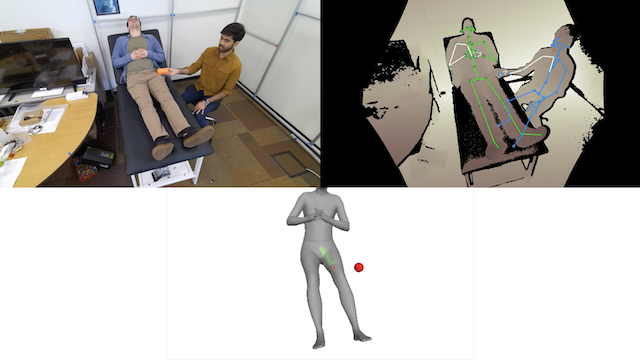
The image below shows a prototype body and pose tracking system that can determine where and how a device is being used (here, a prop ultrasound probe represented by the orange block), and render task-relevant guidance (here, green indicators on a 3D humanoid mesh developed by the Stevens Institute of Technology) to indicate regions of the body that have been successfully scanned vs. those that may have been missed.

FACT
The DARPA FACT (Friction for Accountability in Conversational Transactions) program seeks to develop AI agents that model and mediate conversational dynamics in teams by revealing implicit assumptions and unspoken conflicts between dialogue partners.
Our team's approach is based upon modeling the
In the image below, our system (TRACE) observes 4 participants (one of them online and so not shown in frame) collaboratively construcing a block structure for which each only has partial information. Our TRACE LLM-based agent tracks the beliefs of all parties and the common ground between them to perform interventions to encourage reflection, deliberation, and convergence to common ground regarding the structure being built.

Embodied Computational Metacognition
Embodied Computational Metacognition was a short-term innovative research (STIR) grant from the Army Research Office. We examined and assessed statistical, neural, information theoretic, and logical mechanisms by which "metacognitive" processes can be developed in computers. We focused on developing into AI systems the capacity to detect when their underlying models are inadequate to the situation in which they find themselves, expanding those underlying models to include novel types and concepts, and inferring partial information from novel entities encountered in the environment to achieve specified goals. We adopted an "embodied simulation" view toward processes like object grounding and built upon this to develop and test our method in physical object classification and reasoning tasks.
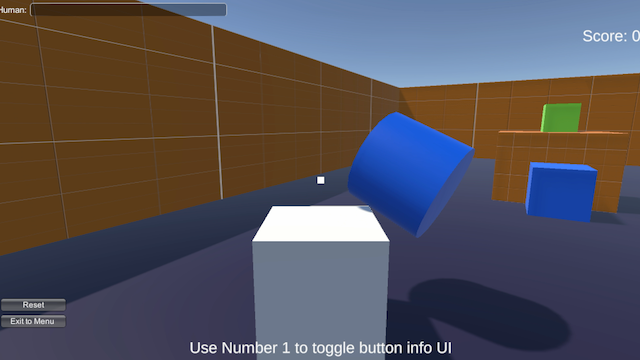
In the image below, an agent (the white cube) performs analogical reasoning over different object types in order to solve a problem in a real-time environment. The agent determines the configuration, or "habitat" the object requires to satisfy a

BabyBAW
BabyBAW (Best of All Worlds) was an NSF-funded EAGER program, part of the NSF 2026 Idea Machine. We draw direct inspiration from developmental psychology to build architectures and platforms that combine neural networks, symbolic reasoning, and embodied simulation for their respective strengths (the "Best of All Worlds" approach). BabyBAW uses the VoxWorld Platform (developed during Communicating with Computers) as its simulation engine and we prototype and develop various diverse tasks to test the BAW architecture(s) on, allow BAW agents to explore and learn in a manner similar to a human infant.
In the image below, BabyBAW learns to stack two blocks in just a few minutes by attending to the height of the structure it builds. Veridical knowledge of parameters like height are one of the advantages provided by embodied simulation methods.

AIDA
AIDA (Active Interpretation of Disparate Alternatives) was a program funded by DARPA that sought to develop automated understanding of events and situations from different perspectives and diverse data sources.
My group's work in the context of AIDA followed on findings from CSU's vision group about the interchangeability of feature spaces in CNN models.
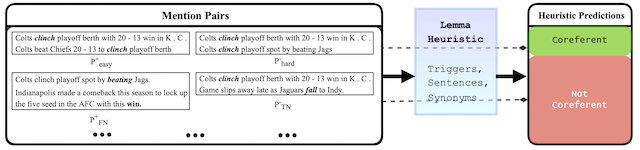
We explored these interchangeability findings in Transformer-based language models and found that using simple affine transformation techniques, we can transfer information between different language models in tasks like coreference resolution and cognate detection. This has protentially profound implications for the properties of language embedding spaces.

CwC
Communicating With Computers (CwC) was a program funded by DARPA to explore communication between humans and machines. The goals of CwC were to build intelligent systems that are not just servants, but collaborators, and can help humans perform a variety of tasks, from construction, to composition and data exploration. CwC funded most of my Ph.D. and postdoc, and the development of the VoxWorld Platform, and I was technical lead on a large collaboration including Brandeis LLC and the CSU Vision lab, that used VoxWorld develop Diana, and multimodal interactive agent that can hear, see, and understand her human partner, and communicates using spoken language and gesture to collaborate on construction tasks in a virtual environment. Multimodal agents like Diana represent a step forward for intelligent systems, toward agents that can not only understand language, but understand the situation and context that they inhabit, whether in the real world or in a mixed-reality environment shared with humans.
Our research from CwC has won awards and been presented at a number of top-tier conferences, including *ACL, NeurIPS, and AAAI. At the AAAI conference in February 2020, we presented a live demo of Diana in New York City. The video below was presented alongside the demo: